
Combat Modern Day Plague in Security with Email Security and Cisco Threat Response Integration
December 19, 2019
Stealthwatch Enterprise and Cisco Threat Response: Bringing machine-scale analysis to human-scale understanding
December 20, 2019Anomaly Detection in Complex Systems: Zero Trust for the Workplace
Zero trust and complexity management represent a new basic combination for a closed-loop approach to anomaly detection and mitigation for critical infrastructures.
This abstract introduces a set of functional blocks that could enable automation and assurance for secure networks. These blocks are designed to reduce/simplify the impact of anomalies and/or anomalous behaviors on complex systems.
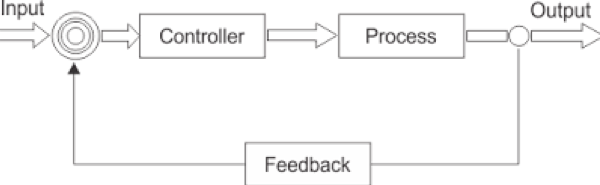
A closed-loop system uses feedback where a portion of the output signal is fed back to the system to reduce errors and improve stability. Access control and intelligent networks can generate data that could be compared with several patterns for gap analysis and feedback retroaction.

Closed-Loop System
Zero Trust is the New Secure Infrastructure Model
Zero trust is the latest and most efficient practice “to securing all access across your networks, applications, and environment. This approach helps secure access from users, end-user devices, APIs, IoT, microservices, containers, and more.
Provide more secure access, protect against gaps in visibility and reduce the attack surface.
Cisco Zero Trust allows you to [1]:
- Consistently enforce policy-based controls
- Gain visibility into users, devices, components, and more across your entire environment
- Get detailed logs, reports, and alerts that can help you better detect and respond to threats.”
Quantitative Complexity Management: A New Approach to Anomaly Detection
Network visibility is essential [2] to zero trust. The scope of assurance systems is to qualify risk from an IT network and security perspective, based on analysis of networks and applications events.
Anomaly detection is the identification of rare items, events, patterns or observations which raise alerts by differing significantly from most of the data. The idea behind anomaly detection is to identify, or anticipate, cyberattacks and malfunctions. Machine learning could be used to detect anomalies very efficiently, as there are different algorithms that can address the topic. This is accomplished by presenting the learning algorithm with tens, hundreds or even thousands of examples of anomalies. And herein lies the problem.
In systems such as large networks or critical infrastructures, the high complexity may hide anomalies which can remain unknown or dormant for extended periods of time. Consequently, training an algorithm to recognize them is impossible. In addition, highly complex systems often comprise thousands or hundreds of thousands of data channels. In a similar context, defining and describing an anomaly may be very difficult and producing a significant set of learning vectors simply not feasible.
To better address anomaly detection, we can introduce new mathematical functions which change the approach. This method is based on the QCM (Quantitative Complexity Management), which can recognize that something unusual is going on without having seen it before.
Complexity is a new multi-dimensional descriptor of systems, networks or processes: it quantifies the amount of structured information within a system and is measured in bits. It has been observed that rapid complexity fluctuations usually correlate with or even anticipate transitions in dynamical systems, providing strong early warning signals. An example is shown below.

Complexity Index Trend Example
(Horizontal axis corresponds to time, the vertical to the complexity index)
However, the early warning feature offered by rapidly changing complexity is only the icing on the cake. In many cases, it is already immensely important to simply know that something harmful or damaging is taking place. Being able to answer the questions “are we under attack?” or “is our system becoming dangerously fragile?” is already a feat in many cases. Finally, QCM also indicates which data channels or variables are responsible for a spike in complexity, making it possible to quickly identify the source of a problem. Basically, this means that we no longer need to define anomalies in advance and then train an algorithm to recognize them. A sudden spike in complexity is an anomaly for which training isn’t necessary. QCM gets it right the first and only time a specific behaviour appears. [3]
An example of a Complexity Map, illustrated below, is relative to the software/electronics subsystem in a car. The map is synthesized in real-time using sensor data taken from the CAN bus.

Complexity Map example for Automotive
The map shows the instantaneous interdependencies between sub-systems, and also indicates which subsystems are the complexity drivers at a given time. These are pointed out by the larger boxes on the diagonal of the map. Knowing which sub-systems or components drive complexity is helpful when it comes to determining the source of problems or malfunctions.
Complexity and resilience are referenced by “ISO/TS 22375:2018 Security and resilience – Guidelines for complexity assessment process.” This document provides guidelines for the application of principles and processes for a complexity assessment of an organization’s systems to improve security and resilience. A real-time assessment can be implemented on different data streams of different sources. The index fluctuations analysis allows an organization to identify potential hidden vulnerabilities of its system and to provide an early indication of complexity-induced risk. [4]
A QCM block can actively drive the complexity of a given system to desired levels. Therefore, in the presence of complexity-increasing anomalies, the QCM controller will compensate, attempting to drive complexity to lower levels. A combination with network assurance systems and QCM is the base of closed-loop architecture.

Network Automation with Closed-Loop Architecture Plus QCM
Conclusion
Because highly complex systems are fragile and often operate close to collapse, it is most important to monitor their complexity. A crisis cannot always be predicted, but it is possible to identify pre-crisis conditions and scenarios, which is what QCM does by producing the mentioned complexity increases and spikes that alert of something anomalous.
Bibliography
[1] Zero Trust Going Beyond the Perimeter
[2] ‘Visibility on the network’ is also a key threat listed in NIST’s 800-27 publication on Zero Trust Architecture, page 22 (U.S. guidelines on cybersecurity for federal agencies).
[3] “Complexity Management: New Perspectives and Challenges for CAE in the 21-st Century”, J. Marczyk, BenchMark Magazine, NAFEMS, July 2008.
[4] The ISO 22375 originates from the UNI 11613 published in 2015.
The post Anomaly Detection in Complex Systems: Zero Trust for the Workplace appeared first on Cisco Blogs.